How We Scaled Our Architecture
Automation is becoming more and more prevalent in the world of online advertising. Online shopping sites may have tens of millions of products in their product catalogs, and making ads for these products manually is simply not feasible. A key part of automation is feed-based advertising, where ads get created automatically based on files containing product information such as names, descriptions, prices, pictures and so on. This blog post describes how we built the infrastructure to handle the volume of image rendering requests our advertising automation requires.
Feed-based advertising and Dynamic Image Templates
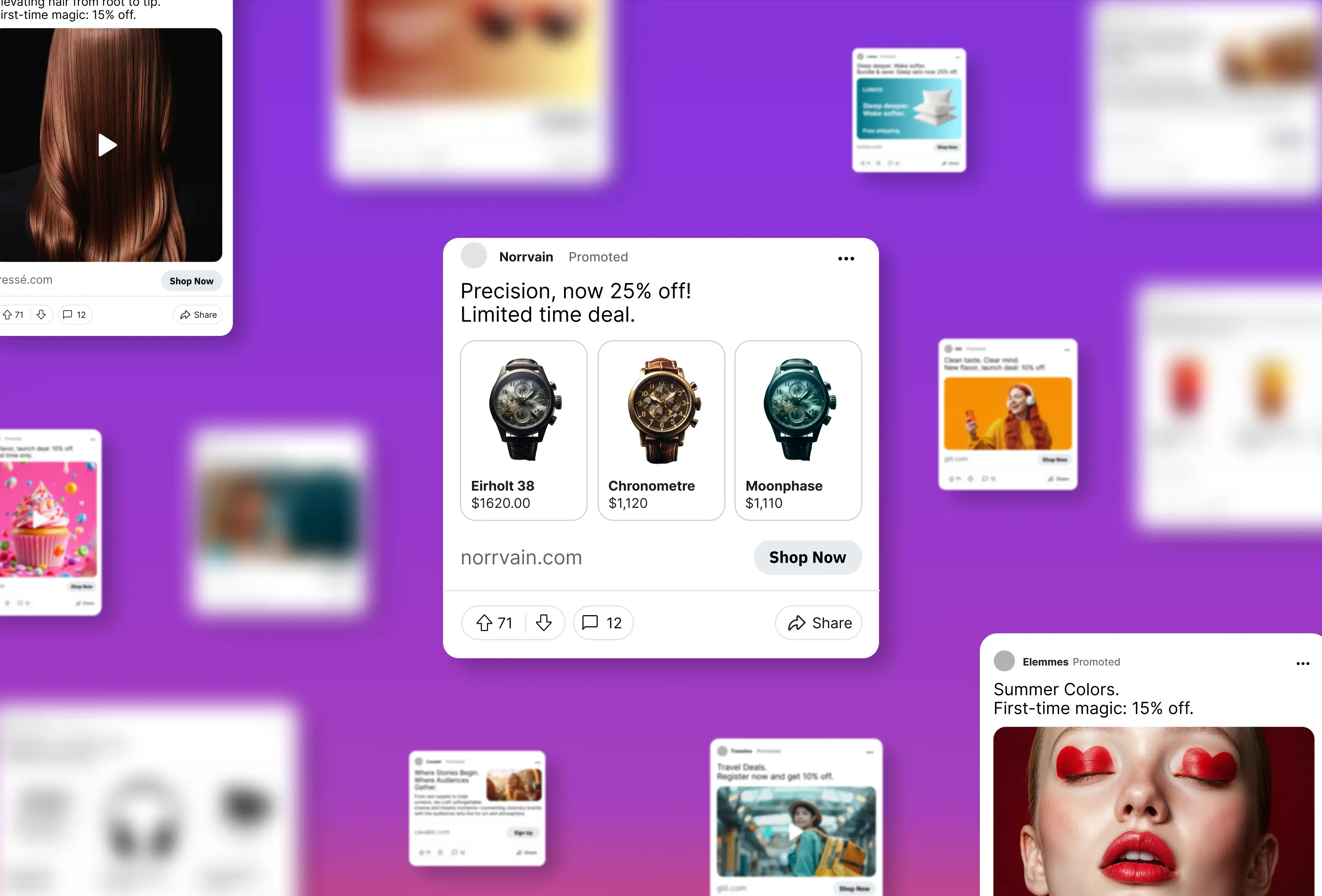
At Smartly.io we’ve developed a feature called Dynamic Image Templates to tackle ad image creation — something that has traditionally been done by hand. A feed’s product images are downloaded and composited into templates, automatically combining them with other product information such as a description, price, a company logo and any other data available in the feed. This involves many computationally intensive steps and rendering a single ad can take hundreds of milliseconds.

An example of an image template
Our initial solution for handling image template processing relied on first processing images for all the products in a feed via task queues, then uploading the images to Amazon S3 (served via CloudFront) and, finally, pointing Facebook to a new version of the feed containing links to the processed images. While this was a decent solution when customers' feeds contained some tens of thousands of products, it quickly turned out that it's simply not a good idea to preprocess all images when there are millions of them. We could have scaled the processing infrastructure horizontally, and we did for a while. However, not all products will ever get shown as ads and, in the end, it's both slow and wasteful to process all the images before they are needed.

The architecture before
By the time we started to look for a new solution, the processing times for larger feeds had grown to several hours. This was simply not acceptable because things like price updates depended on these feed updates, and we saw that customers would soon face situations where they would promote products with obsolete prices, or products that were already out of stock.
On-demand image processing
Rendering images only when Facebook needs them seemed like a good start for a solution. We started to lay out a plan. With an on-demand processing approach, we would have to be prepared for any level of traffic Facebook might throw at us, as traffic would be dependent on how Facebook shows ads to its users. Therefore our high availability and fault tolerance requirements had to be taken to a whole new level.
The simplified idea is that whenever Facebook decides to show a product ad to a user, the product image will be fetched by Facebook. Therefore, just like any other large-scale web platform, ours needed to be prepared for load spikes. The outline of the procedure for processing an image is this:
- Facebook requests an image for a product via HTTP. All product specific data and the ID of the template to be used are encoded in the URL.
- We download the product image from our customer's server.
- We apply the image template to the product image and return the result to Facebook.
Sounds simple enough, right? However, there are a whole bunch of corners you need to consider and polish:
- Easy scalability: Image processing is CPU intensive
- High availability: No single points of failure
- Avoiding unnecessary work:Cache product images, as they may be used by several image templates and we don't want to redownload them or perform denial of service attacks against our customers’ servers by flooding them with requests
- Cache processed images, as Facebook or other parties may ask for them again
- Making sure load spikes don't cause cascading effects to other systems
- Making sure load spikes related to one customer don't affect others
First steps
As our preprocessed images were already being served via CloudFront, we started by simply directing traffic from a CloudFront distribution to a few image processing servers behind round-robin DNS. The initial phase also involved modifying our application code to work via an HTTP API.
As we were increasing the number of image processing servers, it soon became obvious that the DNS load balancing wouldn't scale very far. If a server goes down or is taken down for maintenance, it needs to be removed from the DNS record. Due to the nature of the DNS itself, this takes time. The same goes for adding new servers.
The next step was to add a few HAproxy load balancers to handle the traffic. Proper fault tolerance, for example, is much easier to implement with dedicated load balancers. They can detect when the actual web servers are under too heavy load or malfunctioning, and stop passing requests to them. Similarly, we can easily disable any server at the load balancer and not lose any requests when we need to perform maintenance. Fault tolerance for the load balancers themselves is implemented via a mechanism that redirects traffic from the IP address of a failing load balancer to a healthy one. This mechanism requires some control over the routing of traffic in the data centers we use.
At this stage our system was already pretty scalable and fault tolerant with some caching in place, but this wasn't enough. We wanted to also cache the original product images in order to avoid pounding customers' servers and minimize the time waiting for image downloads. To these ends, we set up some caching forward proxies (powered by Squid) through which all image downloads were directed.
In addition to just caching, Squid has nifty features such as collapsed forwarding. It makes sure that when we receive multiple simultaneous requests to the same product image URL, we make only one request to the customer’s server. It’s quite typical to get several requests for the same product using different image templates at the same time, so this helps a lot in reducing the load on customers’ servers.
The image processors also typically have at least some hundreds of gigabytes of hard drive space, so we decided to cache the original images locally on those nodes as well. High availability was incorporated into the proxy setup too -- all image processors run HAproxy locally so if a Squid proxy goes down, all traffic will go through the others.
Final touches
As we started rolling the new infrastructure out to all customers, it quickly became apparent that CloudFront cost us a lot compared to the benefit we were getting from it. Yes, it was useful as a cache, but most of the other features such as geographic distribution were not very relevant for us as we’re mostly serving images to Facebook. We couldn’t justify the growing costs, so we set up a few Varnish caches between our load balancers and image processors and removed CloudFront from the mix. Still today in October 2016, our monthly caching and load balancing costs are less than one tenth of what we paid for CloudFront in January 2016 even though the number of requests we serve has almost tripled since.

The architecture after
In order to further boost cache hit rates and to utilize resources better, we set up caching in the Nginx web servers run at the image processors themselves. All load balancing is done based on consistent hashing on URLs — the same request should always reach the same Varnish and the same image processor. Therefore a good number of requests that passed through the Varnish caches as misses would be cache hits at the image processors, further reducing the need to reprocess images.
There are several mechanisms that are related to the infrastructure and scalability on the application level as well. If there's an image template that constantly gets used with product images whose downloads take too long, the image template is throttled in order to avoid affecting other templates. Another example is that the image processors cache whatever resources they need to fetch from databases in order to make sure the databases don't get bombarded when there's a load spike.
Conclusion
During the last week of September our image processing system served roughly 1000 requests per second on average. In terms of bandwidth, we typically served a constant load of 500 - 1000 Mbps, spiking at about 3Gbps. Roughly 65% of the requests were Varnish cache hits, and together with the nginx caches, the total cache hit rate was around 75%.
The Squid cache used for downloading original product images has also proven very effective, its hit rate ranging between roughly 50-80%. Average numbers are naturally just average numbers, and spikes can be much higher, at least 10-fold, but they haven't caused many issues recently as we've been able to get rid of bottlenecks.

One week's statistics for the outbound network traffic of one load balancer
The on-demand image processing setup was rolled out in early 2016 and now, just over half a year later, it seems that it's going to scale nicely in the foreseeable future. As tends to be the norm in software development, especially in the insanely fast-paced world of online advertising, use cases change and new bottlenecks emerge, and we'll continue tackling them as we go.



Automation is becoming more and more prevalent in the world of online advertising. Online shopping sites may have tens of millions of products in their product catalogs, and making ads for these products manually is simply not feasible. A key part of automation is feed-based advertising, where ads get created automatically based on files containing product information such as names, descriptions, prices, pictures and so on. This blog post describes how we built the infrastructure to handle the volume of image rendering requests our advertising automation requires.
Feed-based advertising and Dynamic Image Templates
At Smartly.io we’ve developed a feature called Dynamic Image Templates to tackle ad image creation — something that has traditionally been done by hand. A feed’s product images are downloaded and composited into templates, automatically combining them with other product information such as a description, price, a company logo and any other data available in the feed. This involves many computationally intensive steps and rendering a single ad can take hundreds of milliseconds.
An example of an image template
Our initial solution for handling image template processing relied on first processing images for all the products in a feed via task queues, then uploading the images to Amazon S3 (served via CloudFront) and, finally, pointing Facebook to a new version of the feed containing links to the processed images. While this was a decent solution when customers' feeds contained some tens of thousands of products, it quickly turned out that it's simply not a good idea to preprocess all images when there are millions of them. We could have scaled the processing infrastructure horizontally, and we did for a while. However, not all products will ever get shown as ads and, in the end, it's both slow and wasteful to process all the images before they are needed.
The architecture before
By the time we started to look for a new solution, the processing times for larger feeds had grown to several hours. This was simply not acceptable because things like price updates depended on these feed updates, and we saw that customers would soon face situations where they would promote products with obsolete prices, or products that were already out of stock.
On-demand image processing
Rendering images only when Facebook needs them seemed like a good start for a solution. We started to lay out a plan. With an on-demand processing approach, we would have to be prepared for any level of traffic Facebook might throw at us, as traffic would be dependent on how Facebook shows ads to its users. Therefore our high availability and fault tolerance requirements had to be taken to a whole new level.
The simplified idea is that whenever Facebook decides to show a product ad to a user, the product image will be fetched by Facebook. Therefore, just like any other large-scale web platform, ours needed to be prepared for load spikes. The outline of the procedure for processing an image is this:
- Facebook requests an image for a product via HTTP. All product specific data and the ID of the template to be used are encoded in the URL.
- We download the product image from our customer's server.
- We apply the image template to the product image and return the result to Facebook.
Sounds simple enough, right? However, there are a whole bunch of corners you need to consider and polish:
- Easy scalability: Image processing is CPU intensive
- High availability: No single points of failure
- Avoiding unnecessary work:Cache product images, as they may be used by several image templates and we don't want to redownload them or perform denial of service attacks against our customers’ servers by flooding them with requests
- Cache processed images, as Facebook or other parties may ask for them again
- Making sure load spikes don't cause cascading effects to other systems
- Making sure load spikes related to one customer don't affect others
First steps
As our preprocessed images were already being served via CloudFront, we started by simply directing traffic from a CloudFront distribution to a few image processing servers behind round-robin DNS. The initial phase also involved modifying our application code to work via an HTTP API.
As we were increasing the number of image processing servers, it soon became obvious that the DNS load balancing wouldn't scale very far. If a server goes down or is taken down for maintenance, it needs to be removed from the DNS record. Due to the nature of the DNS itself, this takes time. The same goes for adding new servers.
The next step was to add a few HAproxy load balancers to handle the traffic. Proper fault tolerance, for example, is much easier to implement with dedicated load balancers. They can detect when the actual web servers are under too heavy load or malfunctioning, and stop passing requests to them. Similarly, we can easily disable any server at the load balancer and not lose any requests when we need to perform maintenance. Fault tolerance for the load balancers themselves is implemented via a mechanism that redirects traffic from the IP address of a failing load balancer to a healthy one. This mechanism requires some control over the routing of traffic in the data centers we use.
At this stage our system was already pretty scalable and fault tolerant with some caching in place, but this wasn't enough. We wanted to also cache the original product images in order to avoid pounding customers' servers and minimize the time waiting for image downloads. To these ends, we set up some caching forward proxies (powered by Squid) through which all image downloads were directed.
In addition to just caching, Squid has nifty features such as collapsed forwarding. It makes sure that when we receive multiple simultaneous requests to the same product image URL, we make only one request to the customer’s server. It’s quite typical to get several requests for the same product using different image templates at the same time, so this helps a lot in reducing the load on customers’ servers.
The image processors also typically have at least some hundreds of gigabytes of hard drive space, so we decided to cache the original images locally on those nodes as well. High availability was incorporated into the proxy setup too -- all image processors run HAproxy locally so if a Squid proxy goes down, all traffic will go through the others.
Final touches
As we started rolling the new infrastructure out to all customers, it quickly became apparent that CloudFront cost us a lot compared to the benefit we were getting from it. Yes, it was useful as a cache, but most of the other features such as geographic distribution were not very relevant for us as we’re mostly serving images to Facebook. We couldn’t justify the growing costs, so we set up a few Varnish caches between our load balancers and image processors and removed CloudFront from the mix. Still today in October 2016, our monthly caching and load balancing costs are less than one tenth of what we paid for CloudFront in January 2016 even though the number of requests we serve has almost tripled since.
The architecture after
In order to further boost cache hit rates and to utilize resources better, we set up caching in the Nginx web servers run at the image processors themselves. All load balancing is done based on consistent hashing on URLs — the same request should always reach the same Varnish and the same image processor. Therefore a good number of requests that passed through the Varnish caches as misses would be cache hits at the image processors, further reducing the need to reprocess images.
There are several mechanisms that are related to the infrastructure and scalability on the application level as well. If there's an image template that constantly gets used with product images whose downloads take too long, the image template is throttled in order to avoid affecting other templates. Another example is that the image processors cache whatever resources they need to fetch from databases in order to make sure the databases don't get bombarded when there's a load spike.
Conclusion
During the last week of September our image processing system served roughly 1000 requests per second on average. In terms of bandwidth, we typically served a constant load of 500 - 1000 Mbps, spiking at about 3Gbps. Roughly 65% of the requests were Varnish cache hits, and together with the nginx caches, the total cache hit rate was around 75%.
The Squid cache used for downloading original product images has also proven very effective, its hit rate ranging between roughly 50-80%. Average numbers are naturally just average numbers, and spikes can be much higher, at least 10-fold, but they haven't caused many issues recently as we've been able to get rid of bottlenecks.
One week's statistics for the outbound network traffic of one load balancer
The on-demand image processing setup was rolled out in early 2016 and now, just over half a year later, it seems that it's going to scale nicely in the foreseeable future. As tends to be the norm in software development, especially in the insanely fast-paced world of online advertising, use cases change and new bottlenecks emerge, and we'll continue tackling them as we go.



Honestly, we'd rather just show you.
Chat with our team to see how Smartly transforms the fragmented advertising ecosystem into something suspiciously manageable.

%201%20(1)%201%201.avif)
